The inspiration for this blog post is the paper Tam and Engelhardt, 2025 (Tam, 2025), from my postdoc lab under Dr. Barbara Engelhardt. The paper tries to address a highly relevant question in current machine learning research: Given the rise of all these foundation models that generate texts, images, etc., are there any theoretically sound ways to evaluate whether data generated by these models are similarly distributed to real data?. In more plain language: Are the texts/ images generated by GPT-/DallE-type models similar to the texts/ images that we have been generating for years? In more technical language: Are the distributions of the data generated by the foundation models similar to the distributions of the real data?
Now, if our data is simply numerical values derived from some well-defined distributions such as $Normal(\mu, \sigma$), $Beta(\alpha, \beta)$, etc., comparing the two distributions can be done through, most popularly, KL divergence, for which there are analytical formulas if we make assumptions about the distributions. However, when the data becomes high dimension, or even variable dimension as in the case of text data, KL divergence, or any other traditional measure of distance between distributions, becomes unreliable.
The paper itself introduces the concept of Embedded characteristic score to measure the discrepancies between two distributions of data (real vs. AI-generated).
The paper itself will explain the theoretical rationale behind their choice of how the embeded characteristic score should be defined (that it is a legitimate measure of distance–satisfying the triangle inequality, that its mean approximation converges to the formal definition of expectation, that it is bounded).

The paper contains statements for which I am not clear on, and so this blog post is dedicated to helping myself clear up those concepts. Below are the statements I want to understand better:
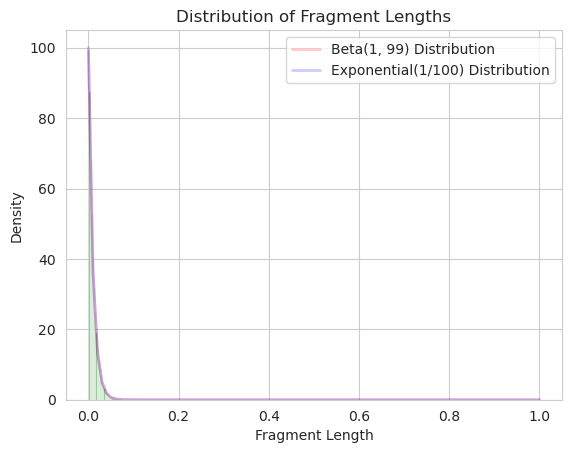
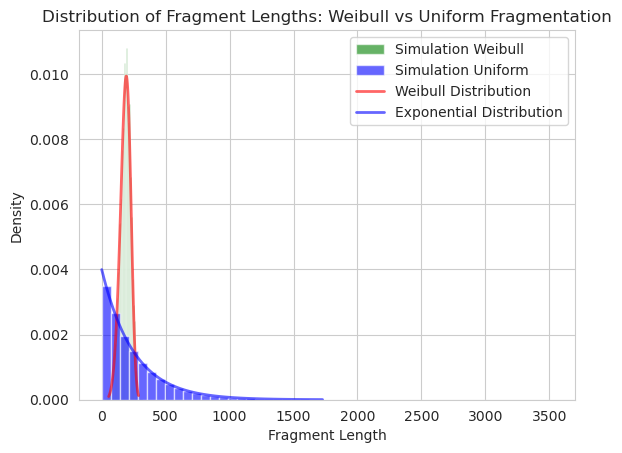
- When the data distribution is heavy-tailed, the higher moments do not exist or do not converge.
- The values of characteristic function of a distribution is always bounded and always exists.
When the data distribution is heavy-tailed, the higher moments do not exist or do not converge
When a distribution is ‘heavy-tailed’, the probability that the variable $\mathbf{X}$ is far from the mean is higher than , say, that of a normal distribution. The $k-$moment, is defined as $E[\mathbf{X}^k]$, when $X$ has a higher chance to take extreme values, the $k-$moment may not exist because $P(\mathbf{X}^k = \inf) \neq 0$.
In practice, moments of a distribution are estimated through the data: $E[\mathbf{X}^k] \approx \frac{1}{n}\sum_{i=1}^{n}x_i^k$. The same procedure can be repeated mulitple times, obtaining multiple estimates of the $k-$moments of $\mathbf{X}$. When the data is heavy-tailed, we could imagine the sampled $x_i^k$ to take very extreme values, and the estimated $k-$moments may vary greatly across different rounds of sampling. Hence, we can state that the higher moments do not “converge”, i.e. the estimated $k-$moments are unreliable when $k$ is high, and $X$ follows a heavy-tailed distribution.
The values of characteristic functions of a distribution is always bounded and always exists
But first, moment generating functions
Before diving in the concept of chracteristic function, we can revisit the concept of moment generating functions (MGF) to understand why characteristic function is different and necessary. I previously wrote about MGF in a separate blog post, but will outline the key idea here for completeness:
- The MGF of a random variable $X$ is defined as $M_X(t)=E[e^{tX}]$. It is function of $t$.
- Depending on how $X$ is distributed, the MGF may or may not exist. For example, if $X$ is from a normal distribution, the MGF exists and has a very nice analytical form. If $X$ is from a Cauchy distribution, the MGF does not exist.
- MGF is aptly named, because if we take the $k-$th derivative of $M_X(t)$ and plug in $t=0$, we will get $E[X^k]$. This can be proven by first writing the Taylor expansion of $e^{tX} = 1 + \frac{tX}{1!} + \frac{t^2X^2}{2!} + \frac{t^3X^3}{3!} + …$, and then taking the expectation of this with respect to $X$, and plugging in $t=0$.
- When we define a random variable $X$, we (or at least I) tend to think of its PDF function, which specifies $P(X=x)$. The PDF defines an unique distribution. The MGF is an alterative way to define the distribution of $X$, i.e. if two distribution of variables $X$ and $Y$ have the same MGF, then they are identically distributed and also have the same PDF $P(X=x)=P(Y=y)$.
- When we compare two distributions, we can also compare their moments, i.e. checking whether $E[X^k] = E[Y^k]$ for all or many values of $k$. If the moments are equal, then the two distributions for $X$ and $Y$ are identical. This is an alternative approach to comparing the distributions of $X$ and $Y$ based on their PDFs, because theoretically, two variables are identically distributed if and only if they have the same moments.
- A tangent but slightly related note: In a separate scenario, when we have data $x_1, x_2, …, x_n$ from a distribution $X$ parameterized by $\theta$ based on our assumption, we tend to first think of Maximum likelihood estimation to find the optimal value of parameters $\theta$ that would maximize the likelihood of observing $P(x_1,…x_p| \theta)$. A different way to find $\theta$ is to estimate the moments of the variable $X$ based on data, i.e. $\hat{X}^k \approx \frac{1}{n}\sum_{i=1}^{n}x_i^k$ for different values of $k$. Then, if our assumed distribution of $X$ allows us to have a analytical form of the moment generating function, then we can find the optimal values for parameter $\theta$ by fitting the values of analytical formula for $k-$moment ($E(X^k)$ based on the MGF) with the approximated values of $\hat{X}^k$. This approach is called the method of moments, which is just a terminology that scared me for the longest time, just because I dont understand what it is until I do.
As you can see, the moment generating function is very useful, but a limitation of MGF is that it does not always exist, as explained above. Tam and Engelhardt, 2025 (Tam, 2025) paper proposes that instead of comparing the moments of two distributions, we can use a related concept called the characteristic function.
Characteristic function definition
The characteristic function of a random variable $X$ is defined as $\phi_X(t) = E[e^{itX}]$, where $i$ is the imaginary unit. The characteristic function is a function of $t$. Similarly to MGF, the characteristic function is a way to define the distribution of $X$, i.e. if two distribution of variables $X$ and $Y$ have the same characteristic function, then they are identically distributed. This is proven in (Lukacs, 1970).
Why is the characteristic function always bounded?
- First, let’s review how a complex number is written in the form of $a+bi$, where $a$ and $b$ are real numbers, and $i$ is the imaginary unit. The magnitude of a complex number $z=a+bi$ is defined as $|z| = \sqrt{a^2+b^2}$.
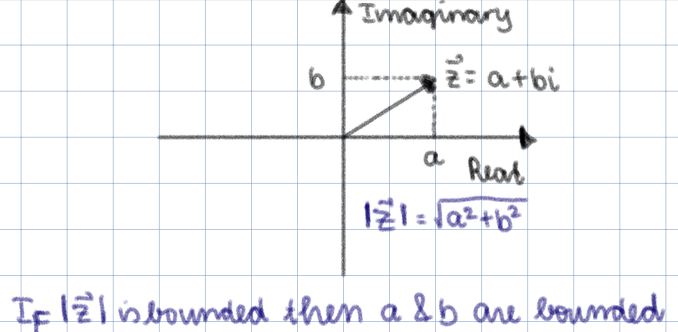
- The characteristic function is bounded because $|e^{itX}| = 1$ for any values of $t$ and $X$. This is because: \(\[ \begin{aligned} e^{itX} &= \, (itX)^0 \;+\; \frac{itX}{1!} \;+\; \frac{(itX)^2}{2!} \;+\; \frac{(itX)^3}{3!} \;+\; \cdots && \quad \text{(Taylor expansion of $e^{itX}$)}\\[6pt] &= \,\Bigl(1 \;-\; \frac{t^2X^2}{2!} \;+\; \frac{t^4X^4}{4!} \;-\; \cdots\Bigr) \;+\; i\Bigl(\frac{tX}{1!} \;-\; \frac{t^3X^3}{3!} \;+\; \cdots\Bigr) && \quad \text{}\\[6pt] &= \,\cos(tX) \;+\; i\,\sin(tX) && \quad \text{(Taylor exansion of $\cos$ and $\sin$)}\\[6pt] \end{aligned} \]\)
Hence, $|e^{itX}| = \sqrt{\cos^2(tX) + \sin^2(tX)} = 1$. Therefore, we can always say that the value of $e^{itX}$ lies on the unit circle in the complex plane, and hence the values of the real or complex part of the characteristic function is bounded.
Concluding remarks
- Just like the PDF, the MGF, the characteristic function is another way to define the distribution of a random variable.
- It is always bounded, and hence, it can be used as a more stable measure of the tail behavior of a distribution.
- This is a very primitive treatment of the characteristic function and how it can be used in understanding the behaviors of a distribution. It is my naive attempt to understand this topic. I encourage you to read the paper (Tam, 2025), especially section 3, for a more detailed explanaion of why it is a more stable measurement of the distance between two distributions. Writing this blog made me reread the paper, and I now have a lot more questions than I originally had (such as how the characteristic function is related to the Fourier transform, and more importantly, what exactly is Fourier Transform that I hear a lot about). I will save those for another blog post.